What is Pintos?
- Training Operating System for x86 Architecture
- Made in 2004 by Stanford Ben Paff
- Support kernel threads, loading and running user programs, file systems, etc.
- Use x86 simulator such as Bochs or QEMU
Project 1
Execute command from command line
- Develops the ability to separate strings of command lines into tokens
- Pintos can’t distinguish between a program and a factor
- Separate program names and factors from each other and store them in the stack
- Pass them to the program
- Result
$ pintos –v -- run ‘echo x’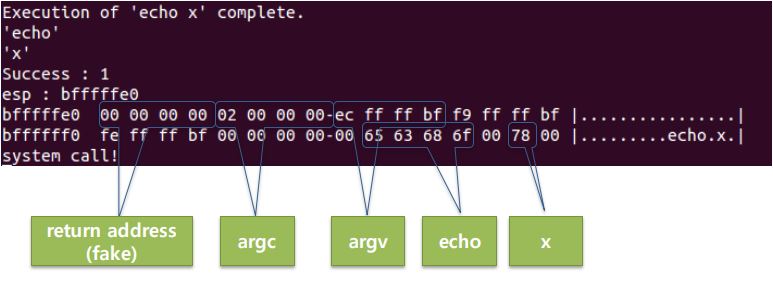
Prevent data from being written to a running file
If the file data of a running user program changes, it is likely that the program will read the changed data differently from the original expected data. If this occurs, write access to running user programs at the OS level should be prevented because the currently running program cannot produce the correct computational results.
- Need to know exactly where the file is running
- Modify the data in running program files to prevent changes
- A function that prevents data change is already implemented in pintos
-
Modify the data in a running file to change only when the program is terminated
- Result
Path : pintos/src/userprog
$ make grade
Project 2
Scheduling
Currently, the scheduler of the pintos is implemented as a round robin. Modify this scheduler to priority scheduling
- Priority Scheduling
- Time Quantum: 40 msec (src/thread.c)
- If the new thread added to the Ready list is higher than the current one, push out the existing thread and allow it to occupy the CPU
- When multiple threads wait to get lock, semaphore, the highest priority thread takes over the CPU
- Result
$ make check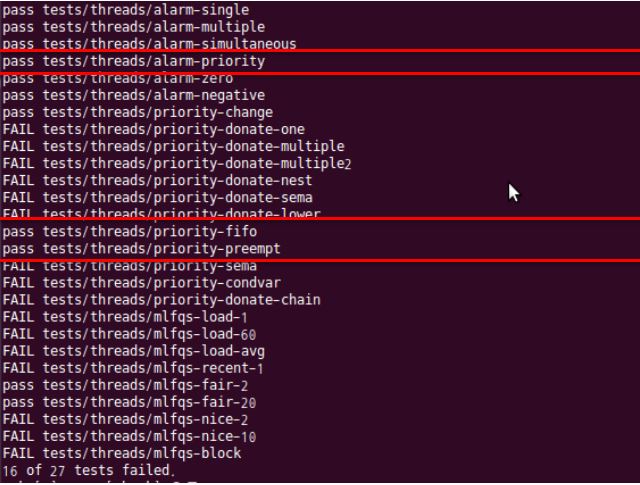
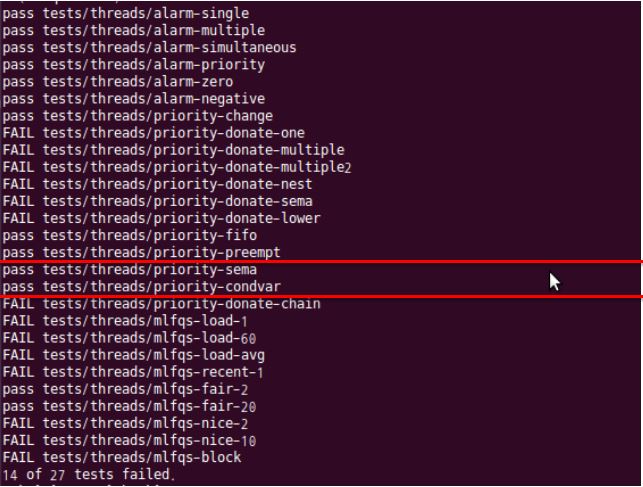
Priority Inversion
- Implement Priority Donation
- Implement Multiple Donation
-
Implement Nested Donation
- Multiple Donation
If more than one thread has more than one lock, a donation may occur by each lock.- Remember the priority of the previous state
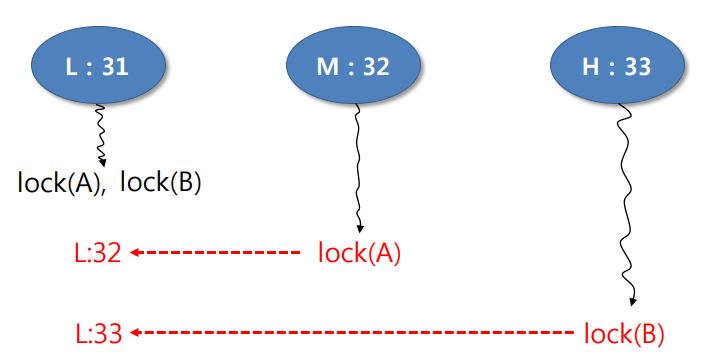

Pintos project #2 Multiple Donation example - Nested Donation

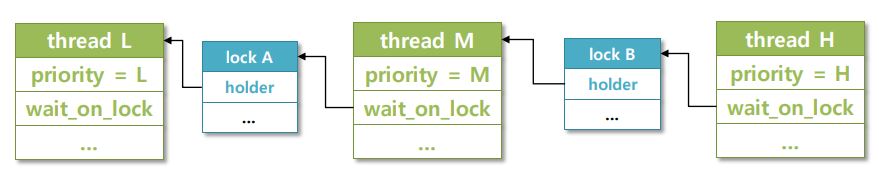
Pintos project #2 Nested Donation example - Result
$ make check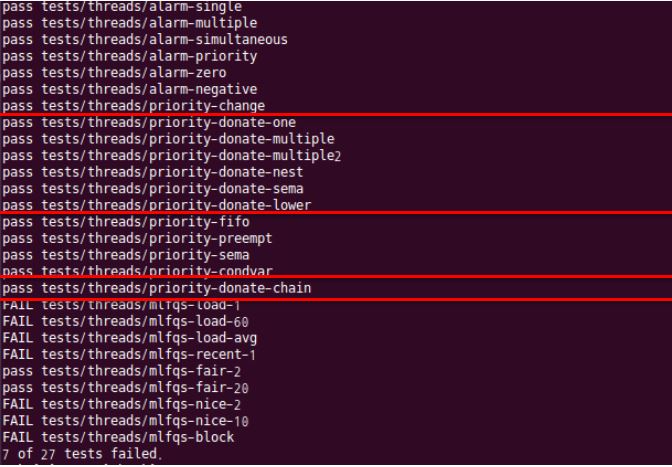
Implement Multi-Level Feedback Queue Scheduler
- Priority
- Nice value
- recent_cpu
-
load_average
- Priority
- The larger the number, the higher the priority
- Initialize when creating threads (default : 31)
- All thread : Recalculate priority every second
\(\begin{align*} priority = PRI_{MAX} – (recent_{cpu} / 4) – (nice * 2) \end{align*}\) - Current thread : Preference recalculation for every 4 clock tick (using formula below)
- 1 tick is 10 msec (src/thread.c)
- Nice value (-20~20)
- Nice (0): No impact on priorities
- Nice (positive) : Reduced priority
- Nice (negative): Increase priority
- Initial value : 0
- recent_cpu
\(\begin{align*} recent_{cpu} = (2 * load_{avg}) / (2 * load_{avg} + 1) * recent_{cpu} + Nice \end{align*}\)- Express how much CPU time has been used recently
- Initial value of the initiator thread is ‘0’, and other threads are the parent’s recent_cpu value.
- Recent_cpu increases by 1 per timer interrupt, recalculating every 1 second
- Implement intread_get_recent_cpu(void) function
Return thread(s) of 100 times of the current recent_cpu
- load_averge
\(\begin{align*} load_{avg} = (59/60) * load_{avg} + (1/60) * ready_{threads} \end{align*}\)- Average number of processes that can be performed in the last 1 minute, using extraordinarily weighted moving average
- Ready_threads : Number of threads running and threads in the ready_list (excluding the lead threads)
- Implementing an intread_get_load_avg(void) function
- Return 100 times the current system load average (round to the need index)
timer_ticks() % TIMER_FREQ == 0
- Result
$ make check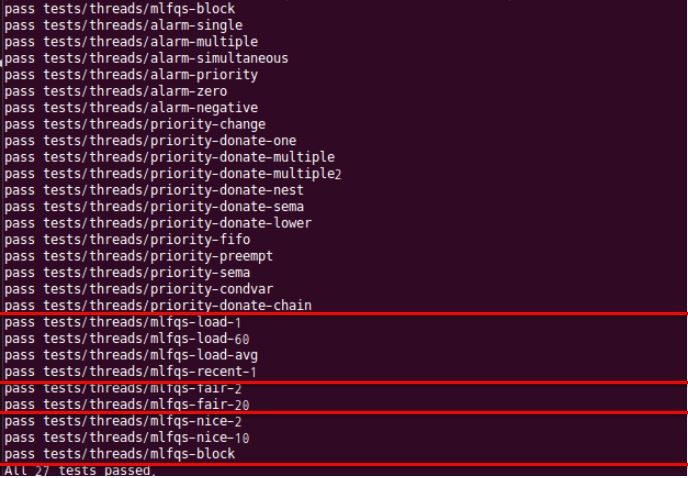
Project 2-1
Implement of demand paging
- Page fault processing Pintos is a page_fault() function for processing when a page fault occurs
Path : pintos/src/userprog/exception.cstatic void page_fault (structure intr_frame *f)- The page_fault processing of the current pintos is generating a “segmentation fault” unconditionally if an error occurs after permisstion or verification of the address, and terminated by kill(-1)
- Delete processing-related to Kill(-1)
- Validate of fault_addr
- Call PageFault Handler Function
Handle_mm_fault (struct vm_entry *vme)
- Page fault handler
pool handle_mm_fault (structure vm_entry *vme)- Handle_mm_fault is a function called for handling when a page fault occurs
- Assign a physical page when a page fault occurs
- Load files from disk onto physical page
load_file (void* kaddr, structure vm_entry *vme) - Map virtual and physical addresses with page tables when loading physical memory is complete
static pool install_page (void *upage, void *kpage,pool writable)
- Write a file to physical memory Path : Pintos/src/vm/page.c
bool load_file (void* kaddr, structure vm_entry *vme)- Function to load pages that exist on disk into physical memory
- Implement a function that reads a page into kaddr by <File, offset> of vme
- Use file_read_at() or file_read() + file_seek()
- If it failed to write all 4KB, fill the rest with zero
- Result
Path : Pintos/src/vm
$ make check
Memory Mapped File
The present pintos are not implemented with mmap() and manmap() functions. In this task, the mmap() and manmap() functions are implemented.
- Implement the mmap() function to load file data into memory by demandpaging
-
Implement the munmap() function to remove file mappings
- Memory-Mapped File
- Treat file I/O as routine memory access by mapping a disk block to a page in memory
- A file is initially read using demand paging.
Subsequent reads/writes to/from the file are treated as ordinary memory accesses - Simplifies file access by treating file I/O through memory rather than read() write() system calls
- Also allows several processes to map the same file allowing the pages in memory to be shared
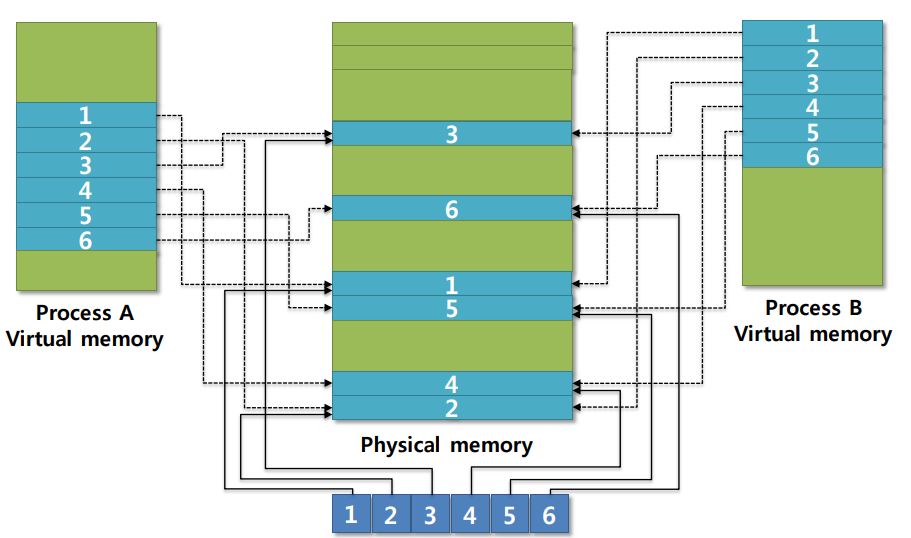
Pintos project #2 Memory-Mapped File - Memory-Mapped I/O
- To allow more convenient access to I/O devices, many computer architectures provide memory-mapped I/O
- In this case, ranges of memory addresses are set aside and are mapped to the device registers
- Read and writes to these memory addresses cause the data to be transferred to and from the device registers
- This method is appropriate for devices that have fast response times, such as video controllers
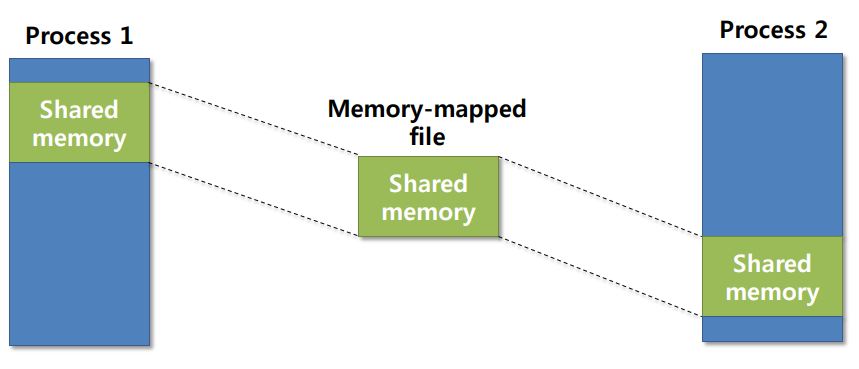
Pintos project #2 Memory-Mapped IO - Result
Path : Pintos/src/vm
$ make check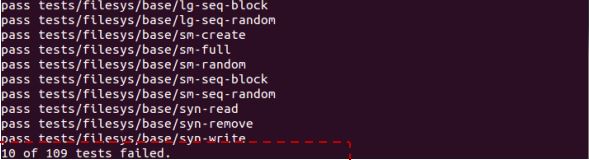
Swapping
- Support Swapping
- Store the selected pages in the swap area when they are included in the data area or stack of the process
- Swap-out pages are reloaded into memory by demand paging
- Modify to operate the page replacement mechanism using LRU-based algorithms
- Result
Path : Pintos/src/vm
$ make check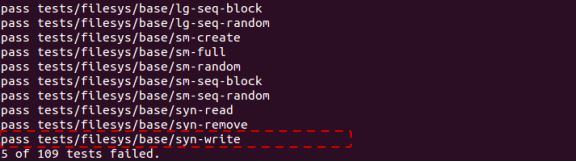
Stack
- Implement scalable stacks
- The current stack is fixed at 4KB
- Modify code to apply a heuristic that determines if access is a valid stack approach or segmentation fault when an address that exceeds the current stack size occurs
- Expand stack if determined by a valid stack approach
- Modify code so that the maximum size of an expandable stack is 8MB
- Result
Path : Pintos/src/vm
$ make check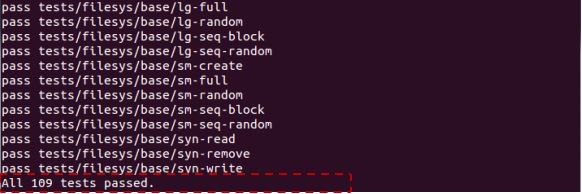
Project 3
Buffer Cache
Buffer cache is a memory area that caches disk blocks. Reduce I/O response time of files by placing disk blocks in the memory area. Currently, buffer cache does not exist in pintos, so disk I/O operations are performed immediately upon file I/O. In this task, we will implement buffer cache and look at performance improvements.
- Filesystem
- Layers that allow the OS to create, access, and archive directories or files
- Manage blockdevices with a certain size of blocks
- Manage block usage through bitmap

Pintos project #3 Linux Filesystem Structure - Result
Path : Pintos/src/filesystem
$ make
$ make check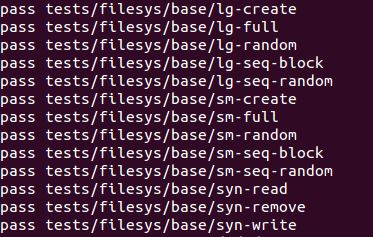
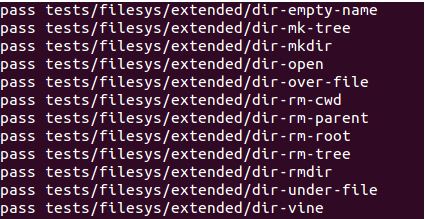
Extensible file
In the current pintos, the size of the file is determined at the time of file creation, and no further changes are possible. This task implements disk blocks to be allocated and used when writing to a file. This allows file size to be expanded without being fixed at creation time.
- Result
Path : Pintos/src/filesystem
$ make
$ make check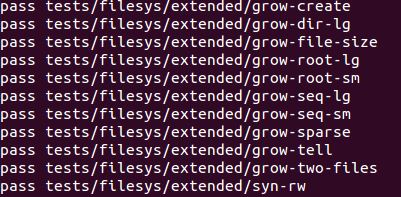
Subdirectory
In the current pintos, files are created only in the root directory as a single layer that only the root directory exists. In this task, we will implement a hierarchy to create files and directories within root directories.
- Result
Path : Pintos/src/filesystem
$ make
$ make check